I am currently very interested in Lambda architecture proposed by Nathan Marz (http://nathanmarz.com/), which represents the state of the art in relation to applications modeling aspects of Big Data. This post provides an overview of Big Data through 3VS model and discusses how the Lambda architecture fits this model. In addition, it presents possible issues related to the evolution of Big Data for Fast Data - a new concept that promises to speed up the processing of vast amounts of information - and discusses tools whose purpose is to facilitate software development in this scenario.
Although there is no formal definition of the size, shape or enforceability encompassing all the idiosyncrasies of Big Data, we can characterize this new computing paradigm according to specific prospects. From a purely computational point of view, big data can be defined as a greater amount of data than the most popular technology is able to process, and this definition is a moving target, ie what today's not Big Data will not be tomorrow's.
Another generally accepted definition describes the big data through three axes, as illustrated in Figure 1. By Volume means the exponential increase in the amount of data presented generated and handled by existing computer systems. Variety comes to different data sources we can have nowadays and the counterpoint between SQL world - where there was a unified framework for describing and accessing data - and NoSQL world - where there are different data models. Finally, the Velocity can be translated by the need for increasingly faster systems that can process this multitude of data - structured and unstructured - in real time.

The first two Vs - Variety and Volume - are usually solved by the use of MapReduce and NoSQL databases. However, to achieve the three axes involved in Big Data, we have to be able to deal not only with a huge volume coming from various data sources, but also to do so at a speed that is close to real time.
Overlooking this problem, Nathan Marz published on its blog a generic architecture that he developed while working at Twitter. Figure 2 presents an overview of the Lambda architecture. The proposal is that the same information - the figure noted as "new data" - will trigger two independent analysis flows. In the first stream, there are two components: the first is called "batch layer", and is responsible for persisting data - possibly in a NoSQL database or in a distributed file system - in a way similar to what we are used to observe; the other component called "serving" layer is responsible for performing analysis or views persisted on these data and make it available through different views. On the other hand, there is "speed" layer which creates real-time analysis. Both layers can be consulted by the final application - for example, an e-commerce site - in addition, data from both layers will still be available for computations, transformations or aggregations.

Figure 2. Overview of Lambda architecture (found in http://lambda-architecture.net/)
The idea of the architecture is that these two layers are complementary, that is, both layers are equally important. As illustrated in Figure 3, the batch layer is always one step behind the real time - since it is expected that the batch layer to make more complicated analysis and these analyzes made over a much larger mass of material (shown in blue in the figure). In addition, after the real-time data is "reached" by batch analysis, the views of real-time information can be simply discarded to make room for more current information.

Figure 3. Relationship between the data analyzed in Batch and Real-time (found in http://jameskinley.tumblr.com/post/37398560534/the-lambda-architecture-principles-for)
Moreover, although it is not explicit in the model, the Lambda architecture recommends the immutability of data in batch layer. In other words, it is expected that no information persisted in the batch layer will be deleted or changed. The idea, interesting but controversial, is illustrated in Table 1 where there is an example consisting of addresses for two users. In this table, rather than each user has only one value to address the address of the users has a timestamp representing its moment of insertion. The idea is that there is no need to modify the data, since the fact that a person change of address does not change that the same person has had elsewhere as an address in the past. Thus, the immutability of data creates a direct relationship between information and time. This has very interesting advantages such as the ability to create different views of the same set of data, the ability to delete or deactivate such views as they become obsolete, greater certainty regarding the data consistency and the ability to retrieve information that is damaged by a programming error.
User
|
Address
|
Timestamp
|
José
|
Lins-SP
|
Março/1983
|
Maria
|
Santo Ângelo-RS
|
Setembro/1986
|
Maria
|
Florianópolis-SC
|
Fevereiro/2015
|
José
|
Florianópolis-SC
|
Fevereiro/2015
|
Table 1. Data Immutability
Although it is not revolutionary in itself, the Lambda architecture offers a good way to organize thinking software architect and facilitate the exchange of information on development projects. Still, some questions may arise when we see this model. We can list the most important:
• In the real world, what kind of application you can use the Lambda architecture?
• MapReduce and Hadoop are not enough for Big Data?
• If the Hadoop is not enough, that tool will use?
• If possible, why not make all processing in real time?
The market is moving toward the Fast Data, and many analysts (http://blogs.wsj.com/cio/2015/01/06/fast-data-applications-emerge-to-manage-real-time-data/) are beginning to discuss what are the requirements of this new stage of Big Data. Among the applications that can benefit from this innovation include:
• Context dependent applications
• Applications dependent on the user's location
• Emergency Applications
• Social networks
In the latter case, many social networks now offer a real-time experience, we can see this when we use twitter or share something on Facebook. On the other hand, there are applications such as Waze and Google itself not offer a real-time update. These applications - probably for some design decision - have a closer MapReduce behavior, since they are capable of attending a tsunami information with high throughput, but with a high latency - that is, new information takes some time to be available.
Therefore, it is important to note, that even being revolutionary, is a huge mistake to use MapReduce paradigm as a solution of all computational problems. This is because, by design this paradigm was developed as a solution to a very specific problem: increasing throughput in data analysis. In other words, the Map Reduce - and frameworks that implement it, such as Hadoop - were thought to analyze a huge amount of data. However, this increase in throughput does not necessarily imply an increase in the speed of this analysis.
Many tools are being developed to solve this problem. Among these tools, we can highlight:
• Apache Storm (https://storm.apache.org/), also developed by Nathan Marz, offers an interesting abstraction for developing real-time applications. His idea is to create a cluster in which developers can publish topologies responsible for performing tasks. As illustrated in Figure 4, each topology consists of two components: the spouts, which are responsible for receiving the streaming data; and bolts that will process this data. Furthermore, the basic information element which flows in this architecture is called a tuple.
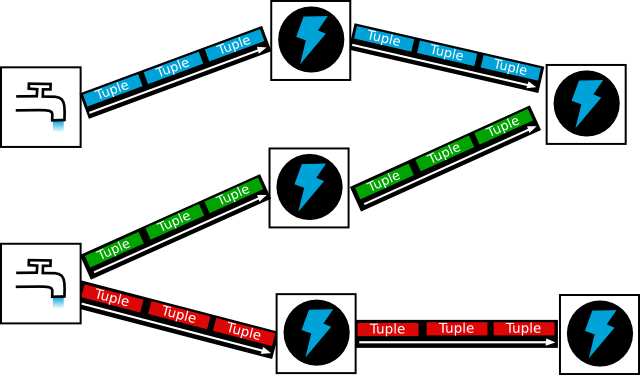
Figure 4. Apache Storm (found in https://storm.apache.org/)
• Apache Kafka (http://kafka.apache.org/), developed in Scala at LinkedIn, is a highly scalable messaging system and in real time. The idea is to create a broker that is located between producers and consumers of messages to manage and accelerate the data analysis. The company Confluent (http://confluent.io/) was created by the same developers of Kafka to offer the application as a service.
• Apache Spark (https://spark.apache.org/) developed by Matei Zaharia while doing his doctorate at UCLA, the Spark uses distributed memory in order to achieve the maximum possible computing directly in main memory . Databricks was also created by the developers of this tool - in fact, Matei is the CTO and Ion Stoica, his doctoral supervisor, is the CEO - to support and lead its development.
• Apache flume (https://flume.apache.org/) also offers an interesting abstraction over the common Map Reduce connecting sources of streaming data persistence in the HDFS via a channel in main memory, as described in Figure 5.

Figure 5. Apache flume (found in http://blog.cloudera.com/blog/2012/10/analyzing-twitter-data-with-hadoop-part-2-gathering-data-with-flume/)
The first conclusion we can infer from the tool list is the Apache Foundation is leading the efforts. This is great because in addition to verifying the quality of developed software, ensures that the codes are available for consultation (https://github.com/apache/storm, https://github.com/apache/kafka, https://github.com/apache/spark, https://github.com/apache/flume) and that we will have a support community. In addition, other features are equally interesting: all applications are designed to operate in highly scalable clusters; most use tools that are also part of the Hadoop like Zookeeper; all use MapReduce in some of its components; some - the Spark and the Flume - tries to carry out their activities in real time through the intensive use of primary memory; others - the Storm - reaches the real time by creating monitors that manage the timing of each activity.
Therefore, it is easy to reach on a conclusion somewhat dangerous: if it is possible, it is best to do it all in real time. However, it is important to remember that work in real time has a cost, which can manifest in different perspectives:
• Best (more expensive) computing environment
• More qualified team
• Higher maintenance costs in the event of changes
• Difficult integration into existing environments
Therefore, when developing for real-time Big Data, the Lambda architecture provides an important starting point. Figure 6 illustrates a possible instance of the Lambda architecture designed from three technologies: Hadoop and HDFS its distributed file system; the database NoSQL Apache HBase; and Apache Storm. Hadoop was used in Batch Layer to store the data in HDFS and MapReduce using compute views, these views can be aggregations of data, scores and statistical analysis - for example, an e-commerce could use these views to compute the full history sales of a particular product. The Storm is used to process the input stream and create more simple views that probably consider just a short time - for example, the same e-commerce can compute what were the most visited products in the last 15 minutes. Finally, in Serving Layer these views are combined and stored in HBase, facilitating access by the application. Interestingly, even these four technologies being developed in Java and related tools (Scala and Clojure), we can use various programming languages to develop the iteration between components.

Figure 6. One possible instance of the Lambda architecture (found in https://www.mapr.com/developercentral/lambda-architecture)
In summary, the addition of another processing layer has great advantages: the data (historical) can be processed with high precision without loss of short-term information, such as alerts and insights provided by real-time layer; furthermore, the computational load a new layer is compensated by the drastic reduction of reading and writing the storage device, which allows much faster access. From a conceptual point of view, even if it is recent, the concepts in Big Data evolve very quickly. There are already talking about articles that there are actually many other Vs needed to describe all facets of this new paradigm. For example, we can mention four Vs recently proposed (https://datafloq.com/read/3vs): Variability, Truthfulness, View and Value.
Finally, the site of the Lambda architecture (http://lambda-architecture.net/) offers many resources to understand more and also provides tool lists that fit for each of the three layers: batch (http://lambda-architecture.net/components/06.30.2014-batch-components/); speed (http://lambda-architecture.net/components/2014-06-30-speed-components/); and serving (http://lambda-architecture.net/components/2014-06-30-serving-components/). In addition, there are many resources to deepen the knowledge of the Lambda architecture, unfortunately most are in English, for example: the great slide Nathan Bijnens (http://lambda-architecture.net/architecture/2013-12-11-a-real-time-architecture-using-hadoop-and-storm-devoxx/), the book "Big Data" Nathan Marz (http://www.manning.com/marz/) and his presentations on YouTube (https://www.youtube.com/watch?v=CEMPG1QvMVw and https://www.youtube.com/watch?v=ucHjyb6jv08).